DCC
Welcome to the webpage of the Digital Competence Centre Implementation Network (DCC-IN). The DCC-IN consists of delegations from the local and thematic DCCs, with the participation of SURF, which has been assigned a supporting role in the implementation plan. DCCs learn from each other by sharing experiences, best practices, and solutions to common challenges.
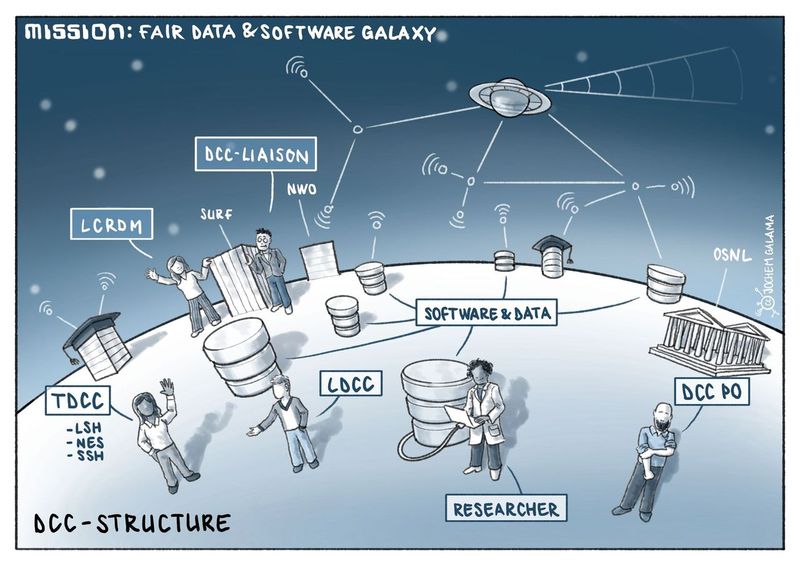
For more information about the start of the Local DCC’s you can read the position paper Implementation Network DCC NL from 2020. This position paper represents a first step for giving the local and thematic DCCs a joint voice through the LCRDM to respond to and anticipate the DCC NL Implementation Network proposed by NWO.
In the infographic of the RDM/RSE landscape in the Netherlands, you will find an overview of 3 stakeholders such as the Local Digital Competence Centres, Researchers and Research performing organisations.
See the 2024 presentation LDCC and DCC-IN position. And for more inspiration about the future of the DCC's, read the 02022 report DCC’s nu en straks (NL) about the Financing Models of the DCC’s.
Find the contact details of the DCC's in the Netherlands in download below.
Updates Implementation Network

DCC-IN newsletter
Stay informed of the latest developments and sign up for the DCC-IN updates.
DCC Spring Training Days
The DCC Spring Training Days are a national collaboration on training and workshops aimed at starting research data stewards and starting researchers. Find all Spring days materials and presentations at Zenodo or check the program below.
DCC Spring Training Days 2026
DCC SPRING Training Days will have its sixt edition in 2026. A variety of topics (11) are offered by your colleagues: from Linked Open Data to Engagement with DMPS, from Pedagogical Skills to AI-tools. from Active Listening to Preregistration. Find the program for the Spring Training Days 2026. All sessions will be in English, and two sessions will be online, the other sessions are (only in person) at SURF Utrecht.
You can register here
Please feel free to share with your colleagues. If you have any questions? info@lcrdm.nl

DCC Spring Training Days 2025
Find all presentations of the Spring Training Days 2025 at Zenodo
Session 1 - Engaging researchers with data management plans by Esther Plomp, TU Delft and Lena Karvovskaya VU Amsterdam.
This workshop aimed at starting research support staff who are beginners or have intermediate knowledge regarding data management plans (DMPs).
Session 2 - Reproducible Workflow by Renate Mattiszik, Saxion University of Applied Sciences; Stephanie van de Sandt and Meron Vermaas, VU Amsterdam
This workshop will teach best practices on how to organize a research project throughout its life cycle using familiar tools as much as possible.
Session 3 - The role of good RDM in accelerating scientific progress by Kristina Hettne, Digital Scholarship Librarian, Leiden University Library; and Alessa Gambardella Data Steward Science, Leiden University
For researchers and support staff, intermediate level. In this workshop we introduced methods and tools to implement the FAIR data principles for good data management and discuss how they accelerate scientific progress.
Session 4 - Basic Principles of Linked Open Data & SPARQL by Kristina Hettne, Digital Scholarship Librarian, Leiden University Library; and Eva Lekkerkerker, Library of the UvA Board and Staff UB.
This workshop is aimed at researchers and research support staff. No prior knowledge or experience is required.
Session 5 - Making qualitative data reusable (includes lunch) by Ricarda Braukmann & Maaike Verburg (DANS)
For Researchers & Research support staff, focused on beginners to the topic. At the end of this workshop, you will be able to evaluate and improve the reusability of qualitative data at all stages of the research data life cycle. You will have a rich toolbelt to your disposal when facing the challenges you may encounter when working with qualitative data.
Session 6 - Practical Pedagogical Techniques for hands-on workshops at Witte Vosch by Lieke de Boer, Community Manager, the Netherlands eScience Center; Fenne Riemslagh, Coordinator Training Programme, the Netherlands eScience Center;
In this workshop, you'll learn a few pedagogical techniques that will help you improve your training sessions. At the end of this training, you will know how to implement peer instruction, monitor student learning, use simple language and avoid jargon, and use analogies, personal stories, and/or humor to make content stick.
Session 7 - Collaborative Lesson Development with Github at Witte Vosch , includes lunch, by Sven van der Burg, (Trainer & Lesson developer @ Netherlands eScience Center)
In this workshop you will learn how you can use GitHub as a central place for storing your lesson material and how you can best organize collaboration using GitHub. At the end of this workshop, you will be able to effectively use GitHub for the lessons you develop.
(Postponed Spring 2025) Session 8 - Anonymization and Pseudonymization introduction by Hanne Vlietinck (Technical Data Steward with background in IT, Hasselt University, Belgium); Afshin Amighi (Lecturer and researcher in Rotterdam University of Applied Science)
This interactive workshop is an introduction of basic techniques and tools for protecting (personal) sensitive data. In the first part, the differences between fully-identifiable data, anonymous and pseudonymised data will be explained. Subjects like techniques, tools and the protection model (K-anonymity, L-diversity, T-closeness) will be handled. You will also get the opportunity to try-out these de-identification techniques in hands-on exercises. In the second part we will handle different levels of access control (authentication and authorization) and best practices on passwords. Possible tools for encryption will be discussed. This part will also be followed by hands-on exercises, during which you consider what measurements you have already taken and what can be improve.
(Postponed Spring 2025) Session 9 - Anonymization and Pseudonymization
ADVANCED (be aware , if you follow the introduction course this afternoon is likely too advanced for you) by Mortaza Shoae Bargh and Afshin Amighi (Lecturers and researchers at Rotterdam University of Applied Science)
For researcher support staff and researchers. Legitimacy of data-driven research and success of data-intensive applications like machine learning and other AI techniques depend heavily on protecting privacy in the design, realization, deployment and maintenance of these studies and systems. Therefore it's important to apply some measures on the data to reduce the risk of disclosing sensitive information as much as possible. In this course we focus on the techniques in Statistical disclosure control to minimize the amount of personal data in data sets.
Session 1 - Engagement: connecting researchers and data stewards
By Esther Plomp (TU Delft) and Lena Karvovskaya (VU Amsterdam)
Session 2 - The role of good RDM in accelarating scientific progress
By Kristina Hettne (Leiden University Library) and Alessa Gambardella (Leiden University)
Session 3 - Introduction to Anonymisation and pseudonymisation
By Hanne Vlietinck (Hasselt University) and Afshin Amighi (Rotterdam University of Applied Sciences)Content Hanne Vlietinck and content Ashfin Amighi
Session 4 - Advanced Anonymisation and pseudonymisation
By Mortaza S. Bargh (Rotterdam University of Applied Sciences)
Session 5 - Practical Pedagogical Techniques for hands-on workshop
By Lieke de Boer (eScience Center) and Mateusz Kuzak (eScience Center)
Session 6 - Organizing your data and software with a reproducible workflow
By Renate Mattiszik (Saxion University of Applied Sciences), Stephanie van de Sandt and Meron Vermaas (VU Amsterdam)
Session 7 - Research Software Management Essentials
By Barbara Vreede (eScience Center), Fenne Riemslagh (eScience Center) and Mateusz Kuzak, (eScience Centre)

DCC implementation network meeting
Find all presentations at Zenodo or check the program below.
On november 6, another LCRDM event took place in Utrecht. Below you'll find an overview of the program, including presentations from the speakers.
Program
Location: Zalen van Zeven, Boothstraat 7, Utrecht
Chair of the Day: Fieke Schoots (Training Coordinator at Health RI)
09:30 – 10:00 Walk-in
10:00 – 11:00
EUR – Erasmus integrated research review
VU – Research Data Management Administration, developing a connected solution
11:00 – 11:30 Break
11:30 – 12:30
TU/e – IT services covering the Research Data Life Cycle
UM – The development of the research project services platform
12:30 – 13:30 Lunch
13:30 – 14:30
Onboarding @ DCC-UG
Onboarding @ UU
14:30 – 15:00 Break (with conversations on buddies and eScience Center offer on support with onboarding the new Research Software Engineers
15:00 – 16:00
Career paths
WUR - Data stewardship model and upcoming update
Career paths
LU – RDM support at Leiden University
16:00 – 17:00 Drinks